
Dear Readers,
In this article,we will see brief introduction regarding to Data Warehouse and Amazon Redshift.

What is a Data Warehouse?
A data warehouse is a central repository of data, which very often originate from disparate sources. Businesses use data warehouses to analyse all of their data in one place and to make more informed decisions.
Data can come into the data warehouse from various sources including relational databases, transactional systems, and other sources.
Data warehouses enable businesses to keep enormous amounts of data in one place since operational and transactional databases are typically not designed for historical reporting or complex queries across terabytes or petabytes of data.
How Do Data Warehouses Work?
Data warehouse Just like a relational database, data warehousing systems define a schema usually consisting of multiple tables which themselves contain columns of some data type (text, number, etc.) While data warehousing systems may look similar to relational databases on the surface, they differ drastically.
Relational database systems are optimized for row-based operations. The common query that selects one or more rows of data can be quite fast since rows are stored next to each other on disk. However, performing an aggregate query on a particular column for the entire table results in a scan of the entire table, which is slow.
Data warehouses take the opposite approach, where their columns are stored next to each other on disk. The benefit of this design is that you can quickly perform analytical queries on a column since the necessary data can be loaded from disk very quickly, without the overhead of the unneeded parts of the table.
Foreign keys and constraints is another area where data warehouses differ drastically from their relational cousins. Unique constraints for say, a social security number provide data integrity in a relational system, ensuring no two SSNs can be added to the same table. However, there are performance costs associated with this enforcement as the engine must validate this unique check whenever new data is added. Data warehouses relax or completely remove constraints like these. In a system which is managing petabytes of data across multiple servers, it is simply too costly to enforce or check constraints like this.
Amazon Redshift
Managers all of the work for setting up , operating and scaling a Data Warehouse.
Includes tasks like provisioning capacity, monitoring and backing up the cluster, and applying patches and upgrades to the Amazon Redshift engine.
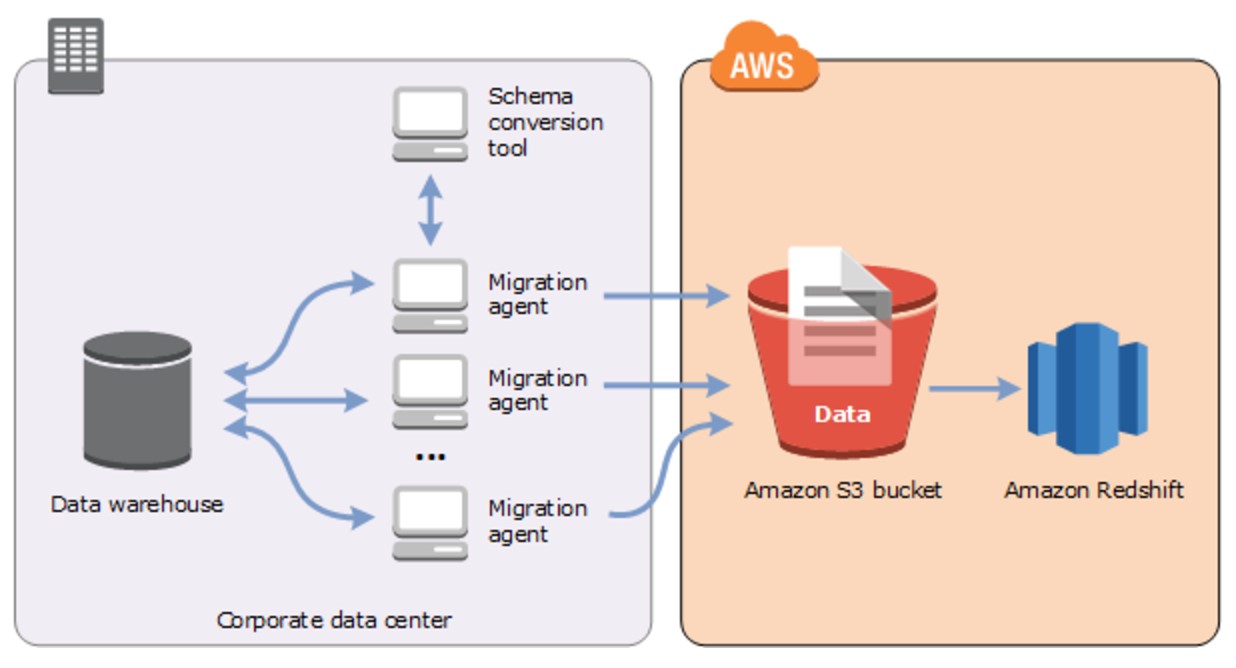
Cluster Management
- Amazon Redshift cluster is a set of nodes, which consists of a leader node and one or more compute nodes.
- Type and number of compute nodes that you need depends on the size of your data, the number of queries you will execute, and the query execution performance that you need.
- Creating and Managing Clusters – Single Node and Multi-Node.
- Reserving Compute Nodes – 1 year or 3 year period.
- Create Cluster Snapshots – Automated and Manual.
Pros and Cons of Amazon Redshift
Your data warehouse will be the foundation for your company’s applications for years to come, so choosing the right technology is crucial. You should make sure the tool you pick is capable of meeting growth and comprehensive requirements of the organization both today and in the future.
Amazon Redshift is a cloud-based, fully managed, petabyte-scale data warehouse service by Amazon Web Services (AWS). In this blog post, we’ll explore the pros and cons of Amazon Redshift to help you make a decision.
Amazon Redshift Pros
- High Performance — Redshift achieves high performance using massive parallelism, efficient data compression, query optimization, and distribution. Using its Massively Parallel Processing (MPP) architecture, Redshift can parallelize data loading, backup, and restore operations. Additionally, queries that you execute get distributed across multiple nodes. Redshift’s columnar storage database is optimized for massive and repetitive type of data, dramatically reduces the input/output (I/O) operations on disk, improving performance.
- Speed— When it comes to loading data and querying it for analytics and reporting, Redshift is extremely fast. MMP allows you to load data at blazing fast speeds.
- Scalability– Scalability is crucial for any data warehousing solution, and Redshift performs well in this arena too. It is horizontally scalable, meaning whenever you need to increase the storage or need it to run faster, you can add more nodes using AWS console or Cluster API, and it will upscale immediately.
- Transparent and Competitive Pricing– Redshift is considerably cheaper than alternatives or an on-premise solution. Redshift has two pricing models that give you the flexibility to categorize the expense as an operational expense or capital expense.
- SQL Interface – The Redshift Query Engine has the same interface as PostgreSQL, which means developers who are already familiar with SQL won’t have a steep learning curve to get going. Since Redshift uses SQL, it works with existing Postgres drivers, easily connecting to most business intelligence tools.
- Security— Redshift comes packed with security features, including various ways to handle access control, Virtual Private Cloud (VPC) for network isolation, data encryption etc.
- You can launch Redshift clusters inside your VPC so you can define security groups and restrict inbound or outbound access to your Redshift clusters.
- AWS Ecosystem– Many businesses are already running their infrastructure on AWS. As you’d expect, Redshift works very well with the rest of the AWS infrastructure tools. For example, when loading or dumping data on S3, Redshift uses MPP to move data very quickly.
Amazon Redshift Cons
- Limited Support for Parallel Upload — Redshift can quickly load data from Amazon S3, relational DynamoDB, and Amazon EMR using Massively Parallel Processing. But Redshift doesn’t support parallel loading from other sources. If you’re working with other data sources, you’ll need to use an ETL solution, JDBC inserts, or scripts to load data.
- Uniqueness Not Enforced— Redshift doesn’t offer a way to enforce uniqueness on inserted data. So if you have a distributed system that writes data on Redshift, you’ll need to handle the uniqueness yourself either by using some method of data deduplication or on the application layer.
Essential features of Redshift
Redshift is known for its emphasis on continuous innovation, but it’s the platform’s architecture that has made it one of the most powerful cloud data warehouse solutions. Here are the six features of that architecture that help Redshift stand out from other data warehouses.
Column-oriented databases
Data can be organized either into rows or columns. What determines the type of method is the nature of the workload.
The most common system of organizing data is by row. That’s because row-oriented systems are designed to quickly process a large number of small operations. This is known as online transaction processing, or OLTP, and is used by most operational databases.
In contrast, column-oriented databases allow for increased speed when it comes to accessing large amounts of data. For example, in an online analytical processing—or OLAP—environment such as Redshift, users generally apply a smaller number of queries to much larger datasets. In this scenario, being a column-oriented database allows Redshift to complete massive data processing jobs quickly.
Massively parallel processing (MPP)
MPP is a distributed design approach in which several processors apply a “divide and conquer” strategy to large data jobs. A large processing job is organized into smaller jobs which are then distributed among a cluster of processors (compute nodes). The processors complete their computations simultaneously rather than sequentially. The result is a large reduction in the amount of time Redshift needs to complete a single, massive job.
End-to-end data encryption
No business or organization is exempt from data privacy and security regulations, and encryption is one of the pillars of data protection. This is especially true when it comes to complying with laws such as GDPR,HIPAA, the Sarbanes-Oxley Act, and the California Privacy Act.
Encryption options in Redshift are robust and highly customizable. This flexibility allows users to configure an encryption standard that best fits their needs. Redshift security encryption features include:
- The option of employing either an AWS-managed or a customer-managed key.
- Migrating data between encrypted and unencrypted clusters.
- A choice between AWS Key Management Service or HSM (hardware security module).
- Options to apply single or double encryption, depending on the scenario.
Network isolation
For businesses that want additional security, administrators can choose to isolate their network within Redshift. In this scenario, network access to an organization’s cluster(s) is restricted by enabling the Amazon VPC. The user’s data warehouse remains connected to the existing IT infrastructure with IPsec VPN.
Fault tolerance
Fault tolerance refers to the ability of a system to continue functioning even when some components fail. When it comes to data warehousing, fault tolerance determines the capacity for a job to continue being run when some processors or clusters are offline.
Data accessibility and data warehouse reliability are paramount for any user. AWS monitors its clusters around the clock. When drives, nodes, or clusters fail, Redshift automatically re-replicates data and shifts data to healthy nodes.
Concurrency limits
Concurrency limits determine the maximum number of nodes or clusters that a user can provision at any given time. These limits ensure that adequate compute resources are available to all users. In this sense, concurrency limits democratize the data warehouse.
Redshift maintains concurrency limits that are similar to other data warehouses, but with a degree of flexibility. For example, the number of nodes that are available per cluster is determined by the cluster’s node type. Redshift also configures limits based on regions, rather than applying a single limit to all users. Finally, in some situations, users may submit a limit increase request.
Thank you for giving your valuable time to read the above information. Please click here to subscribe for further updates
KTEXPERTS is always active on below social media platforms.
Facebook : https://www.facebook.com/ktexperts/
LinkedIn : https://www.linkedin.com/company/ktexperts/
Twitter : https://twitter.com/ktexpertsadmin
YouTube : https://www.youtube.com/c/ktexperts
Instagram : https://www.instagram.com/knowledgesharingplatform




