
Hadoop has many distributions and every distribution has a stack or you can say a collection of technologies/framework that work in conjunction with Hadoop and is knows as HADOOP ECOSYSTEM.
Below is the hadoop ecosystem. Please note there are a plethora of technologies and distributions and the below diagram only has the basic ecosystem tools.
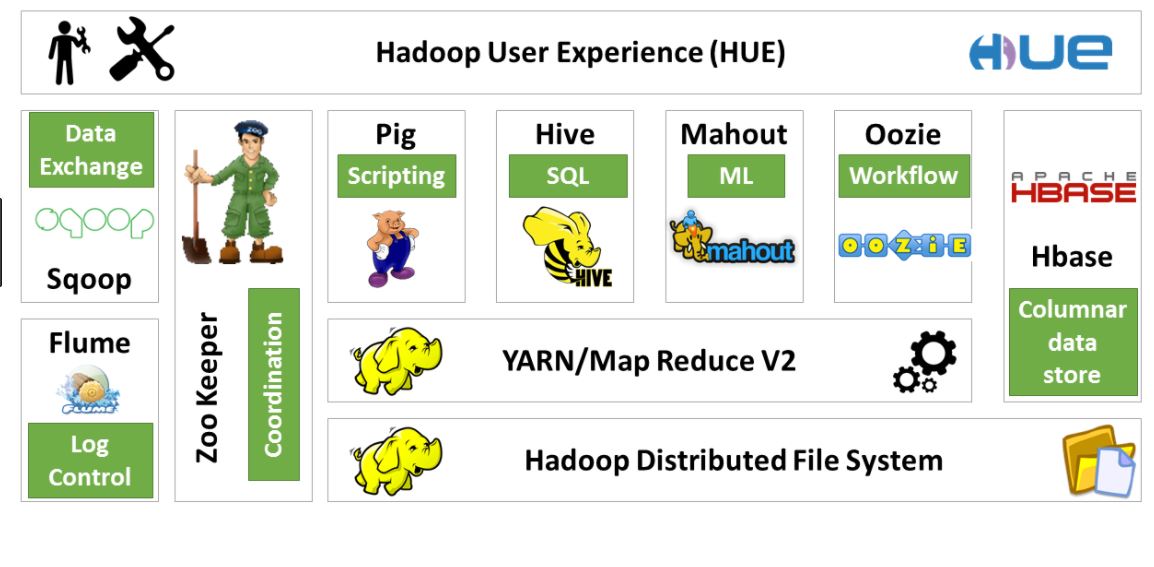
SQOOP: Sqoop is used for data ingestion and to get tables from RDBMS into HDFS and to export from HDFS to RDBMS.Sqoop is important when we have to transfer data between RDBMS and HDFS to perform transformation on HDFS and moved the transformed data back to RDBMS.
FLUME: Flume is used for aggregating and moving large amounts of log data into HDFS.These are mostly streaming data from various social websites, servers or sensors. This unstructured data can be brought into GDFS for analysis by FLUME.
ZOOKEEPER: Zookeeper is used as a coordination service between a number of hosts.Zookeeper is used by nodes to coordinate between themselves for carrying ut any tasks that involve passing messages or instructions between each other
PIG: Pig is a scripting language used by analysts and management to run tasks without having to write lengthy java map reduce codes. Internally, pig scripts are converted into map reduce tasks and the program is executed. Complicated JOIN and GROUP operations which would require complex java programming language can be written easily in Pig.
HIVE: HIVE is used to process structured data in hadoop nejlepší webové stránky. It is basically like a RDBMS of Hadoop. We can also use Hive SQL to query this data stored in HDFS via hive.
MAHOUT: Mahout is used for creating machine learning algorithms.
OOZIE: Oozie is used for scheduling and running jobs in Hadoop. It is helful in breaking down bigger task into many small tasks and running them separately to perform a bigger tasks. It also is useful to perform functionalities like load balancing, failover etc.
HBASE: HBASE is used for storing huge amount of structured data in hadoop in columnar format.
HDFS: Hadoop Distributed File System is the core component of Hadoop which is used to store structured as well as unstructured data into hadoop and every other framework accesses hadoop to retrieve data. Data is secured in HDFS using ACLs.
YARN: YARN (Yet another Resource Negotiator) was introduced in Hadoop 2.0 for managing resource allocation for tasks in hadoop. More deep dive into Yarn and other ecosystem technologies will be seen in later articles.


