
What is BIG DATA?
Introduction:
BigData is current industry problem.
1) Storage Problem (tb, pb, xb…)
2) Processing Problem.
The solution for these problems are called as “Bigdata Storage Solutions” and “Bigdata Processing Solution”. We cannot solve Bigdata problem using traditional RDBMS systems, hence industry today is integrating with Bigdata solutions to solve this problem.
Solutions that were introduced in the market to solve this Bigdata problem:
1) NO SQL- Cassendra, HBASE, MongoDB, Bigtable…
2) Hadoop
HDFS (Distributed Storage)
+
MapReduce( Distributed Processing)
+
YARN( Resource Management- Implemented in 2013)
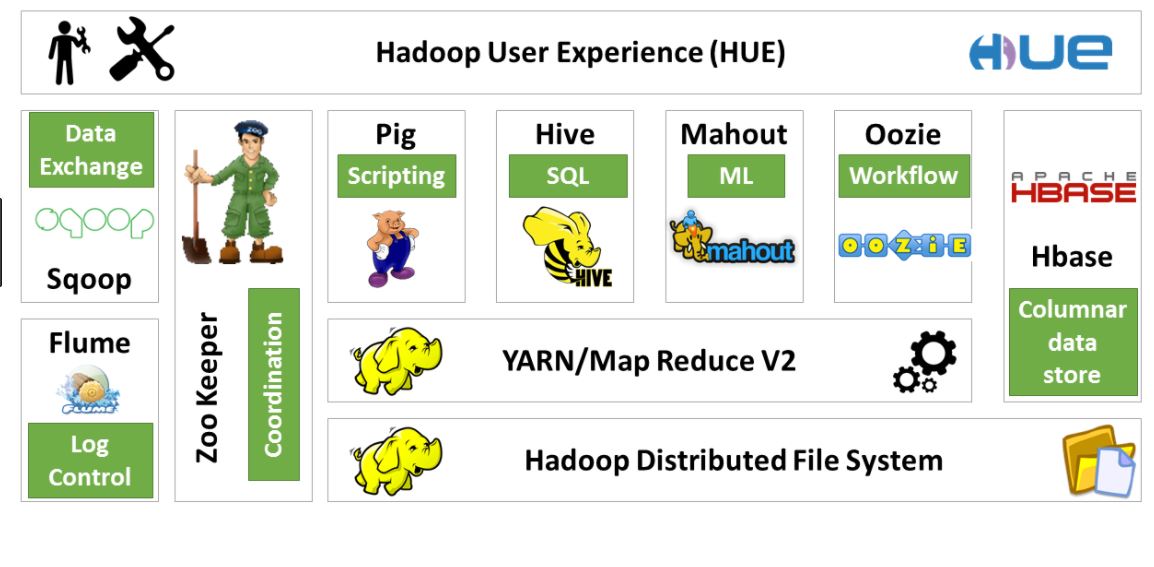
3) Hadoop Ecosystem (Processing Solutions)
- HIVE
- PIG
- SQOOP
- FLUME
- OOZIE
- SPARK
Drawbacks of Traditional Filesytem:
1) Storing large amounts of data.
2) Processing large amounts of data.
3) Data loss during:
– Power Failure
-Network Failure
-Hardware and Software Failure ( Data can be saved only if we have a backup)
4) Metadata- In traditional filesystem, we have Filelevel Metdata but not Contentlevel Metdata. We cannot know the actual contents by looking into the Metadata.
Contentlevel Metadata provides content level and filelevel information which makes search mechanism easy and fast.
E.g Google uses content level Metadata.
History of the Hadoop
-In 1998, Google wanted to build a scalable search engine and hence introduced Google File System (GFS) along with Mapreduce.
-In 2002, Development was started as Nutch project by Doug Cutting and Mike.
Nutch (A Web Crawler):
A Web crawler, sometimes called a spider, is an Internet bot that systematically browses the World Wide Web, typically for the purpose of Web indexing (web spidering).
Web search engines and some other sites use Web crawling or spidering software to update their web content or indices of others sites’ web content. Web crawlers can copy all the pages they visit for later processing by a search engine which indexes the downloaded pages so the users can search much more efficiently.
But data from Nutch project caused Storage and Processing problems. As Nutch was not scalable it was flopped.
-In 2003, Google published white papers for GFS and Mapreduce.GFS as Storage Solution and MapReduce as Processing Solution.
-In 2004, Nutch implemented the google solution to overcome drawbacks of Nutch as
NDFS(Nutch Distributed File System).
-In 2006, Yahoo hired DougCutting and team to build a solution for Yahoo solution and Processing problem and that is how Hadoop had been actually started.
-In 2007, Apache Hadoop ( HDFS, MapReduce) was made open source by Yahoo. Apparently it was modified and performance was increased day to day.
-In 2008, 1 TB of data was sorted by Hadoop in 3.5mins approximately and in 2009 the same data was processed in 62 seconds only.
-Hadoop Ecosystem Tools were started in 2008. Hadoop supports almost 15 plus Filessystems.
Apache Hadoop(framework):
In 2010, Hadoop- 1.x — HDFS and MapReduce was published.
In 2013, Hadoop- 2.x — HDFS, MapReduce and YARN was published.
In 2016, Hadoop- 3.x — HDFS, MapReduce and Yarn was published.
Currently industry is using Hadoop -2.x.
Distributers of Hadoop:
Industry made some modifications by addressing the drawbacks of hadoop and made them as commericials solutions, they are called as “Distributors of Hadoop”
1) Cloudera
2)Hortonworks
3)MapR
4)IBM BigInsights
5)Pivotal HD
6)Amazon EMR(Elastic MapReduce)



Vinod
Good information…
naveen
Good Quality Information
gopi
Good information
Kavya
Good Information
swapna
good information and easily understand
Sai Roja
Nice Artical
Rajewari
Nice Information
sai
good information
Venkatrao
It is very informative and useful
Giselle aga
Appreciation for really being thoughtful and also for deciding on certain marvelous guides most people really want to be aware of.
anvitha
Your info is really amazing with impressive content..Excellent blog with informative concept. Really I feel happy to see this useful blog, Thanks for sharing such a nice blog..
If you are looking for any python Related information please visit our website page!