
What is BigData?
In recent past, BigData has become a buzz word in IT industry. Everyone is talking about this and most of the businesses are trying to leverage this. Then, what is it?
BigData is a concept where data can be stored/processed any limitation on volume and without any constraints on type of data. Also, there would not be any limitation on scaling (both storage & computation).
Why is this grabbing all attention?
In today’s IT world, most of our data solutions revolve around existing RDBMS technologies. When systems are designed with RDBMS, need to abide by the normal forms of RDBMS which actually restricts the data that can be stored ie., only structured data. It is restricting the usage of all other forms of data available in different types and formats like images, videos, emails, documents etc. In fact, there is huge potential of data insight which is being missed out from analytics.
BigData technology provides the ways to store any type of data without any restrictions and process the same with parallel processing framework which will provide better throughput and quick analytics done.
Bigdata concept is addressing following core problem areas or challenges of data
- Volume
- Velocity &
- Variety

In today’s world, data is growing exponentially day by day and resulting data volume in terabytes to zettabytes. As it is required to treat every digital information as data, there is huge increase in usage of unstructured data along with structured which is contributing towards leveraging variety of data. The data is getting added at very fast pace in digital world today due to huge adoption of hand held digital devices by each person and also tremendous increase in digital devices which capture data automatically resulting in machine data.
What is the best solution available?
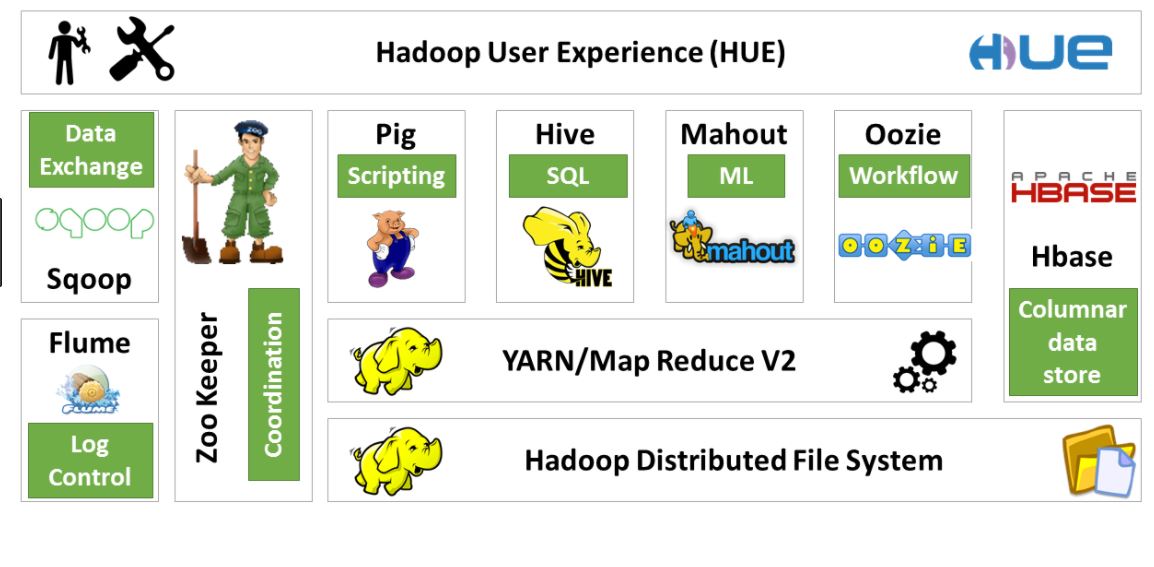
Hadoop
Hadoop is a free, java-based programming framework that supports processing of large data sets in a distributed computing environment. It is part of the Apache project sponsored by ASF(Apache Software Foundation).
Hadoop consists of two key services
- Reliable data storage system using Hadoop Distributed File System(HDFS)
- High Performance parallel data processing framework
Hadoop is a technology which is built on Bigdata concepts providing the solution for all the Bigdata challenges with following design considerations
- New way of storing data in distributed environment
- Process data locally or move processor to data location instead of moving data to the processor
- Handle hardware failures automatically
- Horizontal scaling (both storage & computing)
- Fault Tolerant
- Parallelism part of its operating system
- Relatively inexpensive hardware
- Large files preferred over small
Applications of Hadoop
Most of the businesses are implementing Hadoop in advance data ware housing and advanced analytics. Hadoop is being leveraged along with existing data warehouses to supplement with all Hadoop features.




Meganadha Reddy
Excellent Intro to Hadoop
Thank you.
Regards,
Meganadh
Gugul
Wow.. excellent initiation on Bigdata – hadoop… Good Intro Anup.. Hoping to see more and more articles on Bigdata and Hadoop.
dayaker
nice one very easy to understand
Nama
good one…easy to understand for beginners.
sai
nice article very easy to understand